
Walking the talk of IR35 – by quitting a contract
Should you offer notice on a contract when it’s not compliant? I did, and I’ll tell you why. Reading Time: 6 minutes Winning the Work A while back, I agreed to commence on a contract for…
Read MoreShould you offer notice on a contract when it’s not compliant? I did, and I’ll tell you why. Reading Time: 6 minutes Winning the Work A while back, I agreed to commence on a contract for…
Read More
If you’re on a keto diet, intermittant-fasting, or water-fasting, you might be supplementing with electrolytes to alleviate Keto-flu, heart palpitations, headaches, muscle-shakes, and a variety of other ailments that can happen when you’re restricting your…
There are two reasons you might encounter this issue on AWS Lambda. You’re attempting to import a library that isn’t available by default in the Lambda Runtime environment. In which case you need to include…
A recurring question with AWS Lambda functions is how to properly use third-party binary executables in the Lambda execution environment. A lot of people like to use precompiled binaries but often they’re not available and…
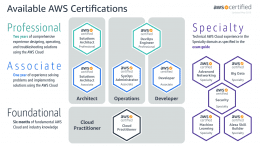
AWS announced on the 28th August 2019 that the entry-level certification – AWS Certified Cloud Practitioner – was now available to be taken remotely from the comfort of your home or office. This certification is…

If you’re using the AWS ACM console to create a certificate, and at the final stage you get this annoying and useless com.amazon.coral.service.InternalFailure, I’ve got the solution for you. You’re probably working in an AWS…

I’ve read a lot of articles lately talking in doomworthy terms about the Off-Payroll working rules from April 2020 that will apply to the private-sector for contractors. Similar rules have been in force for the…
In November AWS announced Reserved Instance Purchase Recommendations in the Cost Explorer. Great! I thought, finally some free native support for what a lot of cost-analysis companies offer at a price. And yet when I look at…

Recently I was frustrated in a Jenkins build when I was running Docker-in-Docker to build and push a container to AWS Elastic Container Registry (ECR). The error on push was a familiar `no basic auth…

This is a true story, although names and details have been removed or changed to protect the awful. Quotes however are verbatim. As often happens when you have ‘DevOps’ in your job title, I received…