Ansible Slack Failure Handler
So you want a simple Slack failure handler for Ansible to ping your alerts channel whenever a deployment fails. Despite a thorough search I couldn’t find any examples that did this adequately, and even the…
So you want a simple Slack failure handler for Ansible to ping your alerts channel whenever a deployment fails. Despite a thorough search I couldn’t find any examples that did this adequately, and even the…

The original ASICS Marathon training plans remain one of the most popular, much loved guides for those preparing for their first marathon (or marathon improvers). Having used these myself, I was slightly frantic recently when…

Courtesy of the AWS subreddit, I was alerted to the fact the recently-updated AWS Service Terms (to covertheir new 3D Lumberyard Game Engine) have included this specific clause: 57.10 Acceptable Use; Safety-Critical Systems. Your use of…
Today AWS announce a long-awaited upgrade to their G2 family of instances – the g2.8xlarge. The big brother of the 2x, which was hitherto the only GPU-backed instance available on the AWS platform. Here’s how…
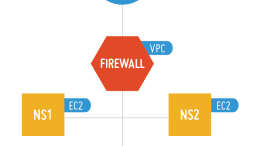
It’s been a long time coming but my company is now fully based on Amazon Web Services EC2 for our web hosting. It’s been a long journey to get here. For more than 15 years we’ve cycled…

If like me you maintain a WordPress website, you might have recently noticed a number of referrals to your site coming from one of the following: buttons-for-website.com, buttons-for-your-website.com, best-seo-offer.com, or some other unknown, dodgy-sounding website…

Developers and businesses around the world will be breathing a huge sigh of relief today as Amazon Web Services finally announced the ability to have invoices generated and charged in one of 11 new local currencies….

A little while ago I wrote up a summary of the distributed.net RC5-72 project. One of my habits over the years has been to run the good old cow client on every new computer I’ve…
When launching an EC2 instance on Amazon Web Services, the EBS volume is set to ‘Delete on Termination’ by default. Most of the time this is fine as you’d often rather make a snapshot of…

History Anyone kicking around the internet since the early days will have heard of distributed.net‘s RC5-72 distributed computing project. Arising from RSA labs Secret-Key Challenge, the project sought to utilise distributed computing power to perform a…